I have suggested several articles to the IsoCpp.org Web site. Some article suggestions were published just a few hours after sending them; others the next day or two, others after a week or two, while other suggestions seemed like lost by anonymous persons in a “black hole”. Who processed those suggestions? Why were those rejected?
This process seems kind of random and unprofessional, and not respectful for the time we put in suggesting articles.
In fact, for suggesting an article, it’s not sufficient to copy-and-paste a link to the content and just click a “Suggest” button. You have to prepare a little document, following a pattern and some editorial guides made available from the IsoCpp Web site. It does take some time.
Then, you click the button to make the suggestion… and it’s like a random coin toss! Will the suggestion be accepted? Will the suggestion be discarded? When? Why? By whom?
The process is clearly broken, and should be fixed, out of respect for the time of the people who made a suggestion, and for what should be a quality Web site that lists links to relevant content.
A possible fix to the process could be like this:
Once you make a suggestion, an email is sent to you, saying that the IsoCpp editorial team has received the suggestion, and will reply in a maximum given period of time: one week, two weeks, whatever. But do give a time limit, and don’t just disappear! I think a 15-day time limit for a reply would be acceptable.
Then, do send a reply to the person suggesting the article, be it positive or negative. But do send a reply! If the suggestion is accepted, say thank you and give a link to the Web page containing the suggestion.
On the other hand, if the suggestion is not accepted, say thank you again, and do give a reason for the refusal. And also give the person suggesting the article an option to further discuss that via email with the editor who refused the suggestion, with the option to discuss that with other editors, too.
Moreover, once a person has a certain number of approved suggestions, let the system automatically approve their suggestions by default. This “privilege level” could be revoked if a certain number of unworthy suggestions or suggestions not relevant for the IsoCpp topics are made.




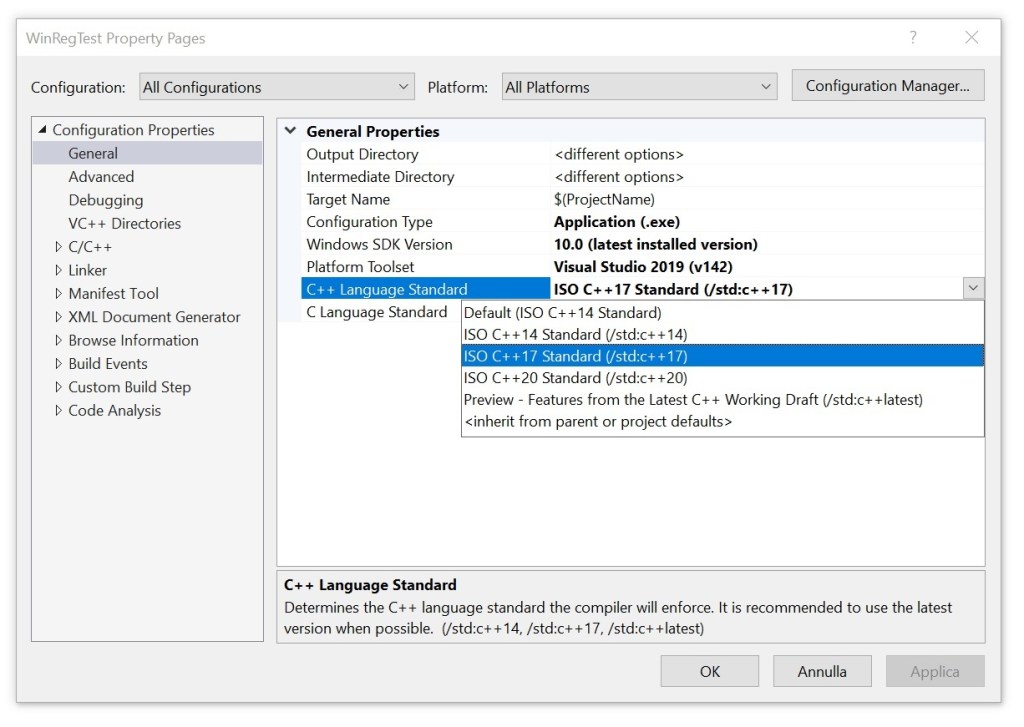


![C4834 warning message emitted by VC++ 2019 in its default C++14 mode, when the return value of a [[nodiscard]] function is discarded.](https://giodicanio.com/wp-content/uploads/2024/01/cpp_vs2019_default_cpp14_nodiscard_warning.png?w=974)