Considering the Unicode conversion code between UTF-16 and UTF-8 using the C++ Standard Library strings and the WideCharToMultiByte and MultiByteToWideChar Win32 APIs, there’s an important aspect regarding the interoperability of the std::string and std::wstring classes at the interface of the aforementioned Win32 APIs.
For example, when you invoke the WideCharToMultiByte API to convert from UTF-16 to UTF-8, the fourth parameter (cchWideChar) represents the number of wchar_ts to process in the input string:
// The WideCharToMultiByte Win32 API declaration from MSDN:
// https://learn.microsoft.com/en-us/windows/win32/api/stringapiset/nf-stringapiset-widechartomultibyte
int WideCharToMultiByte(
[in] UINT CodePage,
[in] DWORD dwFlags,
[in] _In_NLS_string_(cchWideChar)LPCWCH lpWideCharStr,
[in] int cchWideChar,
[out, optional] LPSTR lpMultiByteStr,
[in] int cbMultiByte,
[in, optional] LPCCH lpDefaultChar,
[out, optional] LPBOOL lpUsedDefaultChar
);
As you can see from the function documentation, this cchWideChar “input string length” parameter is of type int.
On the other hand, the std::wstring::length/size methods return a value of type size_type, which is basically a size_t.
If you build your C++ code with Visual Studio in 64-bit mode, size_t, which is a typedef for unsigned long long, represents a 64-bit unsigned integer.
On the other hand, an int for the MS Visual C++ compiler is a 32-bit integer value, even in 64-bit builds.
So, when you pass the input string length from wstring::length/size to the WideCharToMultiByte API, you have a potential loss of data from 64-bit size_t (unsigned long long) to 32-bit int.
Moreover, even in 32-bit builds, when both size_t and int are 32-bit integers, you have signed/unsigned mismatch! In fact, in this case size_t is an unsigned 32-bit integer, while int is signed.
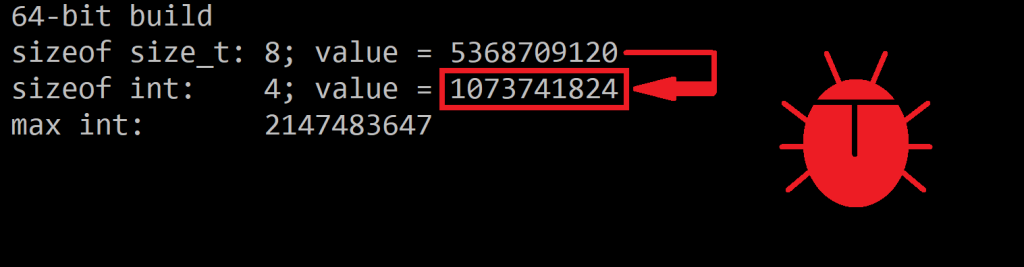
This is not a problem for strings of reasonable length. But, for example, if you happen to have a 3 GB string, in 32-bit builds a conversion from size_t to int will generate a negative number, and a negative length for a string doesn’t make sense. On the other hand, in 64-bit builds, if you a 5 GB string, converting from size_t to int will produce an int value of 1 GB, which is not the original string length.
The following table summarizes these kinds of bugs:
| Build mode | size_t Type | int Type | Potential Bug when converting from size_t to int |
| 64-bit | 64-bit unsigned integer | 32-bit signed integer | A “very big number” (e.g. 5GB) can be converted to an incorrect smaller number (e.g. 5GB -> 1GB) |
| 32-bit | 32-bit unsigned integer | 32-bit signed integer | A “very big number” (e.g. 3GB) can be converted to a negative number (e.g. 3GB -> -1GB). |
Note a few things:
- size_t is an unsigned integer in both 32-bit and 64-bit target architectures (or build modes). However, its size does change.
- int is always a 32-bit signed integer, in both 32-bit and 64-bit build modes.
- This table applies to the Microsoft Visual C++ compiler (tested with VS 2019).
You can have some fun experimenting with these kinds of bugs with this simple C++ code:
// Testing "interesting" bugs with size_t-to-int conversions.
// Compiled with Microsoft Visual C++ in Visual Studio 2019
// by Giovanni Dicanio
#include <iostream> // std::cout
#include <limits> // std::numeric_limits
int main()
{
using std::cout;
#ifdef _M_AMD64
cout << " 64-bit build\n";
const size_t s = 5UI64 * 1024 * 1024 * 1024; // 5 GB
#else
cout << " 32-bit build\n";
const size_t s = 3U * 1024 * 1024 * 1024; // 3 GB
#endif
const int n = static_cast<int>(s);
cout << " sizeof size_t: " << sizeof(s) << "; value = " << s << '\n';
cout << " sizeof int: " << sizeof(n) << "; value = " << n << '\n';
cout << " max int: " << (std::numeric_limits<int>::max)() << '\n';
}
(Note: Bug icon designed by me 🙂 Copyright (c) All Rights Reserved)
So, these conversions from size_t to int can be dangerous and bug-prone, in both 32-bit and 64-bit builds.
Note that, if you just try to pass a size_t value to a parameter expecting an int value, without static_cast<int>, the VC++ compiler will correctly emit warning messages. And these should trigger some “red lights” in your head and suggest that your C++ code needs some attention.
Writing Safer Conversion Code
To avoid the above problems and subtle bugs with size_t-to-int conversions, you can check that the input size_t value can be properly and safely converted to int. In such positive case, you can use C++ static_cast<int> to perform the conversion, and correctly suppress C++ compiler warning messages . Else, you can throw an exception to signal the impossibility of a meaningful conversion.
For example:
// utf16.length() is the length of the input UTF-16 std::wstring,
// stored as a size_t value.
// If the size_t length exceeds the maximum value that can be
// stored into an int, throw an exception
constexpr int kIntMax = (std::numeric_limits<int>::max)();
if (utf16.length() > static_cast<size_t>(kIntMax))
{
throw std::overflow_error(
"Input string is too long: size_t-length doesn't fit into int.");
}
// The value stored in the size_t can be *safely* converted to int:
// you can use static_cast<int>(utf16.length()) for that purpose.
Note that I used std::numeric_limits from the C++ <limits> header to get the maximum (positive) value that can be stored in an int. This value is returned by std::numeric_limits<int>::max().
Fixing an Ugly Situation of Naming Conflict with max
Unfortunately, since Windows headers already define max as a preprocessor macro, this can create a parsing problem with the max method name of std::numeric_limits from the C++ Standard Library. As a result of that, code invoking std::numeric_limits<int>::max() can fail to compile. To fix this problem, you can enclose the std::numeric_limits::max method call with an additional pair of parentheses, to prevent against the aforementioned macro expansion:
// This could fail to compile due to Windows headers
// already defining "max" as a preprocessor macro:
//
// std::numeric_limits<int>::max()
//
// To fix this problem, enclose the numeric_limits::max method call
// with an additional pair of parentheses:
constexpr int kIntMax = (std::numeric_limits<int>::max)();
// ^ ^
// | |
// *------- additional ( ) ------*
Note: Another option to avoid the parsing problem with “max” could be to #define NOMINMAX before including <Windows.h>, but that may cause additional problems with some Windows Platform SDK headers that do require these Windows-specific preprocessor macros (like <GdiPlus.h>). As an alternative, the INT_MAX constant from <limits.h> could be considered instead of the std::numeric_limits class template.
Widening Your Perspective of size_t-to-int Conversions and Wrapping Up
While I took the current series of blog posts on Unicode conversions as an occasion to discuss these kinds of subtle size_t-to-int bugs, it’s important to note that this topic is much more general. In fact, converting from a size_t value to an int can happen many times when writing C++ code that, for example, uses C++ Standard Library classes and functions that represent lengths or counts of something (e.g. std::[w]string::length, std::vector::size) with size_type/size_t, and interacts with Win32 APIs that use int instead (like the aforementioned WideCharToMultiByte and MultiByteToWideChar APIs). Even ATL/MFC’s CString uses int (not size_t) to represent a string length. And similar problems can happen with third party libraries as well.
A reusable convenient C++ helper function can be written to safely convert from size_t to int, throwing an exception in case of impossible meaningful conversion. For example:
// Safely convert from size_t to int.
// Throws a std::overflow_error exception if the conversion is impossible.
inline int SafeSizeToInt(size_t sizeValue)
{
constexpr int kIntMax = (std::numeric_limits<int>::max)();
if (sizeValue > static_cast<size_t>(kIntMax))
{
throw std::overflow_error("size_t value is too big to fit into an int.");
}
return static_cast<int>(sizeValue);
}
Wrapping up, it’s also worth noting and repeating that, in case of strings of reasonable length (not certainly a 3 GB or 5 GB string), converting a length value from size_t to an int with a simple static_cast<int> doesn’t cause any problems. But if you want to write more robust C++ code that is prepared to handle even gigantic strings (maybe maliciously crafted on purpose?), an additional check and potentially throwing an exception is a good safer option.

3 thoughts on “Beware of Unsafe Conversions from size_t to int”