Pay attention to the target of the address-of (&) operator!
Suppose that you have some data stored in a std::vector, and you need to pass it to a function that takes a pointer to the beginning of the data, and in addition the data size or element count.
Something like this:
// Input data to process
std::vector<int> myData = { 11, 22, 33 };
//
// Do some processing on the above data
//
DoSomething(
??? , // beginning of data
myData.size() // element count
);
You may think of using the address-of operator (&) to get a pointer to the beginning of the data, like this:
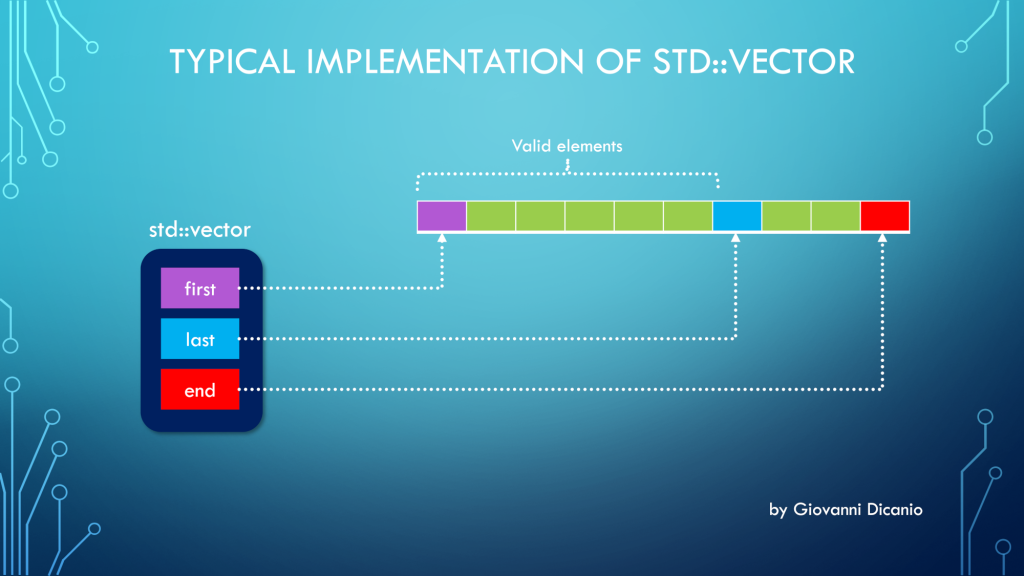
But the above code is wrong. In fact, if you use the address-of operator (&) with a std::vector instance, you get the address of the “control block” of std::vector, that is the block that contains the three pointers first, last, end, according to the model discussed in a previous blog post:
Taking the address of a std::vector (&v) points to its control block
Luckily, if you try the above code, it will fail to compile, with a compiler error message like this one produced by the Visual C++ compiler in VS 2019:
Error C2664: 'void DoSomething(const int *,size_t)':
cannot convert argument 1
from 'std::vector<int,std::allocator<int>> *' to 'const int *'
Types pointed to are unrelated; conversion requires reinterpret_cast, C-style cast or function-style cast
What you really want here is the address of the vector’s elements stored in contiguous memory locations, and pointed to by the vector’s control block.
To get that address, you can invoke the address-of operator on the first element of the vector (which is the element at index 0): &v[0].
// This code works
DoSomething(&myData[0], myData.size());
As an alternative, you can invoke the std::vector::data method:
DoSomething(myData.data(), myData.size());
Now, there’s a note I’d like to point out for the case of empty vectors:
If size() is 0, data() may or may not return a null pointer.
CppReference.com
I would have preferred a well-defined behavior such that, when size is 0 (i.e. the vector is empty), data() must return a null pointer (nullptr). This is the good behavior that is implemented in the C++ Standard Library that comes with VS 2019. I believe the C++ Standard should be fixed to adhere to this intelligent behavior.
First, let’s reveal the mystery of the “fixed 24-byte sizeof”; then, let’s see how to properly get the total size, in bytes, of all the elements stored in a std::vector.
Someone was modernizing some legacy C++ code. They had an array defined like this:
int v[100];
and they needed the size, in bytes, of that array, to pass that value to some function. They used sizeof(v) to get the previous array size.
When modernizing their code, they chose to use std::vector instead of the above raw C-style array. And they still used sizeof(v) to retrieve the size of the vector. For example:
The output they got when building their code in release mode with Visual Studio 2019 was 24. They also noted that they always got the same 24 output, independently from the number of elements in the std::vector!
This is clearly a bug. Let’s try to shed some light on it and show the proper way of getting the size of the total number of elements stored in a std::vector.
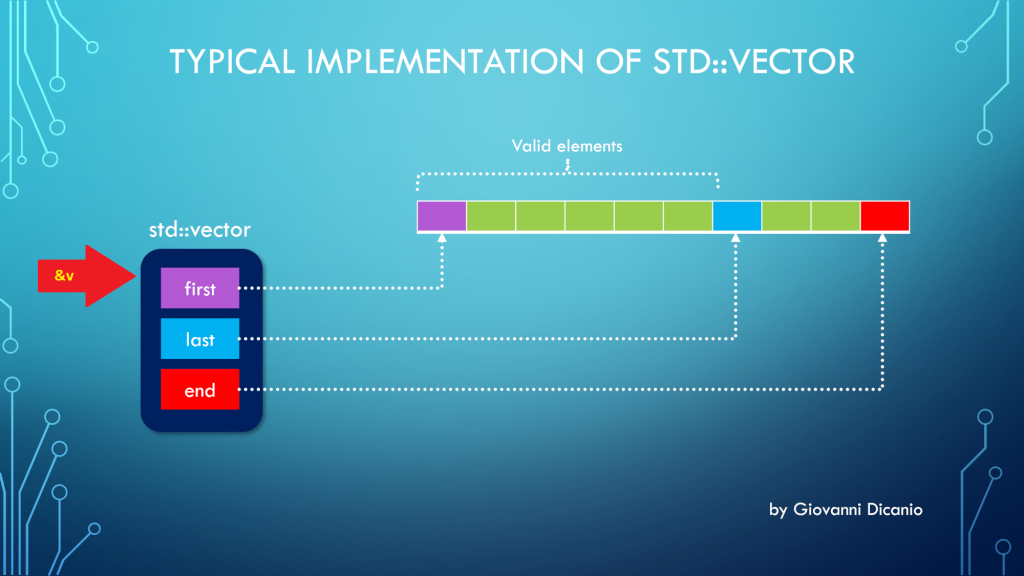
First, to understand this bug, you need to know how a std::vector is implemented. Basically, at least in Microsoft STL implementation (in release builds, and when using the default allocator1), a std::vector is made by three pointers, kind of like this:
Typical implementation of std::vector with three pointers: first, last, end
first: points to the beginning of the contiguous memory block that stores the vector’s elements
last: points one past the last valid element stored in the vector
end: points one past the end of the allocated memory for the vector’s elements
Spelunking inside the Microsoft STL implementation, you’ll see that the “real” names for these pointers are _Myfirst, _Mylast, _Myend, as shown for example in this part of the <vector> header:
An excerpt of the <vector> header that comes with Microsoft Visual Studio 2019
So, when you use sizeof with a std::vector instance, you are actually getting the size of the internal representation of the vector. In this case, you have three pointers. In 64-bit builds, each pointer occupies 8 bytes, so you have a total of 3*8 = 24 bytes, which is the number that sizeof returned in the above example.
As you can see, this number is independent from the actual number of elements stored in the vector. Whether the vector has one, three, ten or 10,000 elements, the size of the vector’s internal representation made by those three pointers is always fixed and given by the above number (at least in the Microsoft’s STL implementation that comes with Visual Studio2).
Now that the bug has been analyzed and the mystery explained, let’s see how to fix it.
Well, to get the “size of a vector”, considered as the number of bytes occupied by the elements stored in the vector, you can get the number of elements stored in the vector (returned by the vector::size method), and multiply that by the (fixed) size of each element, e.g.:
//
// v is a std::vector<int>
//
// v.size() : number of elements in the vector
// sizeof(int) : size, in bytes, of each element
//
size_t sizeOfAllVectorElementsInBytes = v.size() * sizeof(int);
To write more generic code, assuming the vector is not empty, you can replace sizeof(int) with sizeof(v[0]), which is the sizeof the first element stored in the vector. (If the vector is empty, there is no valid element stored in it, so the index zero in v[0] is out of bounds, and the above code won’t work; it will probably trigger an assertion failure in debug builds.)
In addition, you could use the vector::value_type type name member to get the size of a single element (which would work also in the case of empty vectors). For example:
using IntVector = std::vector<int>;
IntVector v(100);
// Print the number of bytes occupied
// by the (valid) elements stored in the vector:
cout << v.size() * sizeof(IntVector::value_type);
To be even more generic, a helper template function like this could be used:
//
// Return the size, in bytes, of all the valid elements
// stored in the input vector
//
template <typename T, typename Alloc>
inline size_t SizeOfVector(const std::vector<T, Alloc> & v)
{
return v.size() * sizeof(std::vector<T, Alloc>::value_type);
}
//
// Sample usage:
//
std::vector<int> v(100);
std::cout << SizeOfVector(v) << '\n';
// Prints 400, i.e. 100 * sizeof(int)
Bonus Reading
If you want to learn more about the internal implementation of std::vector (including how they represent the default allocator with an “empty class” using the compressed pair trick), you can read these two interesting blog posts on The Old New Thing blog:
CString easily allows loading strings from resources “out of the box”. Let’s try to implement this feature for std::wstring.
As discussed in the previous blog post, CString offers convenient methods for Windows C++ programming, including those to load strings from resources.
What Is a String Resource and Why Should You Care?
Basically, in a Windows Win32 C++ application you can store your strings (like messages for the user) as resources, and then reference them in your C++ code via their IDs. If you want to localize your application for a different language, a translator can take the string resources and translate them into the destination language. The C++ source code remains the same, as it references strings not by their language-specific literal form (e.g. “Cannot access the Registry key XYZ”), but using language-neutral resource IDs (e.g. IDS_CANNOT_ACCESS_REGISTRY_KEY_XYZ).
Accessing String Resources via the LoadString(W) API
To access a Unicode (UTF-16) string resource, you can use the LoadStringW Win32 API.
Loads a string resource from the executable file associated with a specified module and either copies the string into a buffer with a terminating null character or returns a read-only pointer to the string resource itself.
From that paragraph, we get that there are two different behaviors available for this API:
Copy the string resource into a user-provided buffer.
Return a read-only pointer to the string resource itself.
Behavior #1: Copying the String Resource into a User-provided Buffer
The first behavior is shown several times in Microsoft documentation. For example, the doc page about LoadStringW refers to the following sample code:
Example code for LoadString referenced by the official Microsoft documentation
Basically, the idea here is to create a TCHAR buffer, and invoke LoadString to load the string resource into that buffer:
In Unicode builds, TCHAR becomes WCHAR (i.e. wchar_t), and LoadString becomes LoadStringW.
One of the problem of this kind of code is that the buffer is pre-allocated with a given fixed size. Then, what happens if the string read from resources is larger than the pre-allocated buffer? The string is silently truncated, as per the official MS documentation about the cchBufferMax parameter:
The string is truncated and null-terminated if it is longer than the number of characters specified.
This could make the UI ugly if it is just a user message string that gets truncated; or it can become a much more serious bug if the truncated string is something like the format specifier for some printf-like function.
Moreover, in that code there is no check on the return value of LoadString. So, if the function fails, the buffer could contain garbage, and that could cause other bugs. (Although, I understand that often MS documentation doesn’t include error checking; but it’s important to point that out, as often people copy-paste code from MS doc samples, and silent bugs are introduced in their own code.)
In addition, it’s important to remember to properly scale the “sizeof” the destination buffer, dividing it by sizeof(TCHAR), which is sizeof(WCHAR) == 2 (bytes) in Unicode builds. Failing to do so would cause additional buffer overflow problems.
You can use a std::wstring of proper size, and pass a pointer to the internal string characters instead of using a raw wchar_t array, but the aforementioned problems still remain.
Behavior #2: Getting a Read-only Pointer to the String Resource
To me the behavior #2 (which is: get a read-only pointer to the string resource itself) is what leads to better and easier code (despite some type cast). However, it’s not very clear from the current MS documentation how to operate the LoadStringW API in this “behavior #2” mode.
So, let’s explain that here. Let’s start with the function declaration:
int LoadStringW(
[in, optional] HINSTANCE hInstance,
[in] UINT uID,
[out] LPWSTR lpBuffer,
[in] int cchBufferMax
);
To enable behavior #2 (i.e. return a read-only pointer to the string resource itself), you need to pass 0 (zero) for the last parameter cchBufferMax.
If you pass zero for cchBufferMax, the LoadStringW API says: “Hey, the caller wants me to just return a read-only pointer to the string resource itself, with no deep-copies in a user-provided buffer. Ok, let’s do that!”
Where does the API get the information about the destination string pointer? In other words: Where can the LoadStringW API write the string resource’s address? Well, it uses the third parameter for that: lpBuffer.
However, there’s a gotcha here (that I think is not well documented in the official MS web page). Basically, you need to create a const wchar_t pointer that will store the address of the resource string (which is read-only, hence the const):
// Pointer to the start of the string resource
const wchar_t* pchStringBegin = nullptr;
Then you need to pass the address of this pointer as the lpBuffer parameter to LoadStringW: &pchStringBegin. Note that, in this way, you are using a double-indirection, i.e. a pointer-to-a-pointer. Since the lpBuffer parameter is declared as LPWSTR (i.e. wchar_t*), you have a type mismatch for this parameter. In fact, LoadStringW expects a simple wchar_t* pointer; but you are passing a pointer-to-a-wchar_t-pointer (double indirection). However, this type mismatch is needed and expected by the behavior #2, so in this case you can safely use reinterpret_cast to make the C++ compiler happy about that type mismatch.
So, the LoadStringW call can look like this:
// Invoke LoadStringW, requesting a pointer
// to the beginning of the string resource
int cchStringLength = ::LoadStringW(
hInstance,
resourceId,
reinterpret_cast<PWSTR>(&pchStringBegin),
0);
Note that the string resource is not necessarily NUL-terminated! But, thankfully, on success, the LoadStringW API returns the number of characters (as count of wchar_ts) in the string resource.
So, you can use these two pieces of information to build a std::wstring instance to safely store the string resource:
The pointer to the start of the string resource
The number of wchar_ts in the string resource
In code, this becomes:
if (cchStringLength > 0) // LoadStringW succeeded
{
// Create a std::wstring storing the string loaded from resources
return std::wstring(pchStringBegin, cchStringLength);
}
On failure, LoadStringW returns zero. Then you can choose if you want to throw an exception, log an error message, return an empty string to the user, return a std::optional<std::wstring>, or whatever.
Wrapping Up: An Easy-to-Use and Hard-to-Misuse Helper Function for Loading String Resources into std::wstring
To wrap up this blog post, this is a nice LoadStringFromResources reusable C++ function that you can invoke to load string resources into std::wstring:
//
// Load a string resource into a std::wstring
//
[[nodiscard]] std::wstring LoadStringFromResources(
_In_opt_ HINSTANCE hInstance,
_In_ UINT resourceId
)
{
// Pointer to the first character of the string.
// NOTE: *Not* necessarily null-terminated!!
const wchar_t* pchStringBegin = nullptr;
// Invoke LoadStringW, requesting a pointer
// to the beginning of the string resource itself
const int cchStringLength = ::LoadStringW(
hInstance,
resourceId,
reinterpret_cast<PWSTR>(&pchStringBegin),
0);
ATLASSERT(cchStringLength >= 0);
if (cchStringLength > 0)
{
// Success
return std::wstring(pchStringBegin, cchStringLength);
}
else
{
// Failure: Throw an exception
// const DWORD error = ::GetLastError();
AtlThrowLastWin32();
}
}
Revisiting one of my first blog posts from 2010. Should you pick CString or std::string? Based on what context (ATL, MFC, cross-platform code)? And why?
It’s interesting to revisit that post today toward the end of 2023, more than 10 years later.
So, should we use CString or std::string class to store and manage strings in our C++ code?
Well, if there is a need of writing portable C++ code, the choice should be std::string, which is part of the C++ standard library.
(Me, on January 4th, 2010)
Still true today. Let’s also add that we can use std::string with Unicode UTF-8-encoded text to represent international text.
But, in the context of C++ Win32 programming (using ATL or MFC), I find CString class much more convenient than std::string.
These are some reasons:
Again, I think that is still true today. Now let’s see the reasons why:
1) CString allows loading strings from resources, which is good also for internationalization.
Still valid today. (You have to write additional code to do that with STL strings.)
2) CString offers a convenient FormatMessage method (which is good for internationalization, too; see for example the interesting problem of “Yoda speak” […])
Again, still true today. Although in C++20 (20+ years later than MFC!1) they added std::format. There’s also something from Boost (the Boost.Format library).
3) CString integrates well with Windows APIs (the implicit LPCTSTR operator comes in handy when passing instances of CString to Windows APIs, like e.g. SetWindowText).
Still valid today.
4) CString is reference counted, so moving instances of CString around is cheap.
Well, as discussed in a previous blog post, the Microsoft Visual C++ compiler and C++ Standard Library implementation have been improved a lot since VS 2008, and now the performance of STL’s strings is better than CString, at least for adding many strings to a vector and sorting the string vector.
5) CString offers convenient methods to e.g. tokenize strings, to trim them, etc.
This is still a valid reason today. 20+ years later, with C++20 they finally added some convenient methods to std::string, like starts_with and ends_with, but this is very little and honestly very late (but, yes, better late than ever).
So, CString is still a great string option for Windows C++ code that uses ATL and/or MFC. It’s also worth noting that you can still use CString at the ATL/MFC/Win32 boundary, and then convert to std::wstring or std::string for some more complex data structures (for example, something that would benefit from move semantics), or for better integration with STL algorithms or Boost libraries, or for cross-platform portions of C++ code.
I used and loved Visual C++ 6 (which was released in 1998), and its MFC implementation already offered a great CString class with many convenient methods including those discussed here. So, the time difference between that and C++20 is more than 20 years! ↩︎
Let’s see how STL strings, ATL CString and strings coming from a custom pool allocator perform in a couple of interesting contexts (string vector creation and sorting).
Basically, the pool allocator maintains a singly-linked list of chunks, and string memory is carved from each chunk just increasing a string pointer. When there isn’t enough memory available in the current chunk to serve the requested allocation, a new chunk is allocated. The new chunk is safely linked to the previous chunk list maintained by the allocator object, and the memory for the requested string is carved from this new chunk. At destruction time, the linked list of chunks is traversed to properly release all the allocated memory blocks.
I measured the execution times to create and fill string vectors, and the execution times to sort the same vectors.
TL;DR: The STL string performance is great! However, you can improve creation times with a custom pool allocator.
The execution times are measured for vectors storing each kind of strings: STL’s wstring, ATL’s CString (i.e. CStringW in Unicode builds), and the strings created using the custom string pool allocator.
This is a sample run (executed on a Windows 10 64-bit Intel i7 PC, with code compiled with Visual Studio 2019 in 64-bit release build):
String benchmark: STL vs. ATL’s CString vs. custom string pool allocator
As you can note, the best creation times are obtained with the custom string pool allocator (see the POL1, POL2 and POL3 times in the “Creation” section).
For example:
String type
Run time (ms)
ATL CStringW
954
STL std::wstring
866
Pool-allocated strings
506
Sample execution times for creating and filling string vectors
In the above sample run, the pool-allocated strings are about 47% faster than ATL’s CString, and about 42% faster than STL’s wstring.
This was expected, as the allocation strategy of carving string memory from pre-allocated blocks is very efficient.
Regarding the sorting times, STL and the custom pool strings perform very similarly.
On the other hand, ATL’s CString shows the worst execution times for both creation and sorting. Probably this is caused by CString implementation lacking optimizations like move semantics, and using _InterlockedIncrement/_InterlockedDecrement to atomically update the reference count used in their CoW (Copy on Write) implementation. Moreover, managing the shared control block for CString instances could cause an additional overhead, too.
Historical Note: I recall that I performed a similar benchmark some years ago with Visual Studio 2008, and in that case the performance of ATL’s CString was much better than std::wstring. I think move semantics introduced with C++11 and initially implemented in VS2010 and then refined in the following versions of the C++ compiler, and more “programming love” given to the MSVC’s STL implementation, have shown their results here in the much improved STL string performance.
Benchmark Variation: Tiny Strings (and SSO)
It’s also possible to run the benchmark with short strings, triggering the SSO (to enable this, compile the benchmark code #define’ing TEST_TINY_STRINGS).
Here’s a sample run:
String benchmark with tiny strings: STL vs. ATL vs. custom string pool allocator
As you can see in this case, thanks to the SSO, STL strings win by an important margin in both creation and sorting times.
Now, let’s assume that you have a Windows C++ code base using MFC or ATL, and the CString class. In Unicode builds (which have been the default in VS since Visual Studio 2005!), CString is a UTF-16 string class. You want to convert between that and the C++ Standard Library’s std::wstring.
How can you do that?
Well, in the Visual C++ implementation of the C++ standard library on Windows, std::wstring stores Unicode UTF-16-encoded text. (Note that, as already discussed in a previous blog post, this behavior is not portable to other platforms. But since we are discussing the case of an ATL or MFC code base here, we are already in the realm of Windows-specific C++ code.)
So, we have a match between CString and wstring here: they use the same Unicode encoding, as they both store Unicode UTF-16 text! Hooray! 🙂
So, the conversion between objects of these two classes is pretty simple. For example, you can use some C++ code like this:
//
// Conversion functions between ATL/MFC CString and std::wstring
// (Note: We assume Unicode build mode here!)
//
#if !defined(UNICODE)
#error This code requires Unicode build mode.
#endif
//
// Convert from std::wstring to ATL CString
//
inline CString ToCString(const std::wstring& ws)
{
if (!ws.empty())
{
ATLASSERT(ws.length() <= INT_MAX);
return CString(ws.c_str(), static_cast<int>(ws.length()));
}
else
{
return CString();
}
}
//
// Convert from ATL CString to std::wstring
//
inline std::wstring ToWString(const CString& cs)
{
if (!cs.IsEmpty())
{
return std::wstring(cs.GetString(), cs.GetLength());
}
else
{
return std::wstring();
}
}
Note that, since std::wstring’s length is expressed as a size_t, while CString’s length is expressed using an int, the conversion from wstring to CString is not always possible, in particular for gigantic strings. For that reason, I used a debug-build ATLASSERT check on the input wstring length in the ToCString function. This aspect was discussed in more details in my previous blog post on unsafe conversions from size_t to int.
In this post I’ll discuss another interesting scenario: Consider the case that you have a C++ Windows-specific code base, for example using ATL or MFC. In this portion of the code the CString class is used. The code is built in Unicode mode, so CString stores Unicode UTF-16-encoded text (in this case, CString is actually a CStringW class).
On the other hand, you have another portion of C++ code that is standard cross-platform and uses only the standard std::string class, storing Unicode text encoded in UTF-8.
You need a bridge to connect these two “worlds”: the Windows-specific C++ code that uses UTF-16 CString, and the cross-platform C++ code that uses UTF-8 std::string.
Windows-specific C++ code interacting with portable standard C++ code
For example, consider the conversion from UTF-16 CString to UTF-8 std::string.
The function declaration looks like this:
// Convert from UTF-16 CString to UTF-8 std::string
std::string ToUtf8(CString const& utf16)
Inside the function implementation, let’s start with the usual check for the special case of empty strings:
std::string ToUtf8(CString const& utf16)
{
// Special case of empty input string
if (utf16.IsEmpty())
{
// Empty input --> return empty output string
return std::string{};
}
Then you can invoke the WideCharToMultiByte API to figure out the size of the destination UTF-8 std::string:
// Safely fail if an invalid UTF-16 character sequence is encountered
constexpr DWORD kFlags = WC_ERR_INVALID_CHARS;
const int utf16Length = utf16.GetLength();
// Get the length, in chars, of the resulting UTF-8 string
const int utf8Length = ::WideCharToMultiByte(
CP_UTF8, // convert to UTF-8
kFlags, // conversion flags
utf16, // source UTF-16 string
utf16Length, // length of source UTF-16 string, in wchar_ts
nullptr, // unused - no conversion required in this step
0, // request size of destination buffer, in chars
nullptr, // unused
nullptr // unused
);
if (utf8Length == 0)
{
// Conversion error: capture error code and throw
...
}
Then, as already discussed in previous articles in this series, once you know the size for the destination UTF-8 string, you can create a std::string object capable of storing a string of proper size, using a constructor overload that takes a size parameter (utf8Length) and a fill character (‘ ‘):
// Make room in the destination string for the converted bits
std::string utf8(utf8Length, ' ');
To get write access to the std::string object’s internal buffer, you can invoke the std::string::data method:
Now you can invoke the WideCharToMultiByte API for the second time, to perform the actual conversion, using the destination string of proper size created above, and return the result utf8 string to the caller:
// Do the actual conversion from UTF-16 to UTF-8
int result = ::WideCharToMultiByte(
CP_UTF8, // convert to UTF-8
kFlags, // conversion flags
utf16, // source UTF-16 string
utf16Length, // length of source UTF-16 string, in wchar_ts
utf8Buffer, // pointer to destination buffer
utf8Length, // size of destination buffer, in chars
nullptr, // unused
nullptr // unused
);
if (result == 0)
{
// Conversion error: capture error code and throw
...
}
return utf8;
I developed an easy-to-use C++ header-only library containing compilable code implementing these Unicode UTF-16/UTF-8 conversions using CString and std::string; you can find it in this GitHub repo of mine.
Converting from size_t to int can cause subtle bugs! Let’s take the Win32 Unicode conversion API calls introduced in previous posts as an occasion to discuss some interesting size_t-to-int bugs, and how to write robust C++ code to protect against those.
For example, when you invoke the WideCharToMultiByte API to convert from UTF-16 to UTF-8, the fourth parameter (cchWideChar) represents the number of wchar_ts to process in the input string:
// The WideCharToMultiByte Win32 API declaration from MSDN:
// https://learn.microsoft.com/en-us/windows/win32/api/stringapiset/nf-stringapiset-widechartomultibyte
int WideCharToMultiByte(
[in] UINT CodePage,
[in] DWORD dwFlags,
[in] _In_NLS_string_(cchWideChar)LPCWCH lpWideCharStr,
[in] int cchWideChar,
[out, optional] LPSTR lpMultiByteStr,
[in] int cbMultiByte,
[in, optional] LPCCH lpDefaultChar,
[out, optional] LPBOOL lpUsedDefaultChar
);
As you can see from the function documentation, this cchWideChar “input string length” parameter is of type int.
On the other hand, the std::wstring::length/size methods return a value of type size_type, which is basically a size_t.
If you build your C++ code with Visual Studio in 64-bit mode, size_t, which is a typedef for unsigned long long, represents a 64-bit unsigned integer.
On the other hand, an int for the MS Visual C++ compiler is a 32-bit integer value, even in 64-bit builds.
So, when you pass the input string length from wstring::length/size to the WideCharToMultiByte API, you have a potential loss of data from 64-bit size_t (unsigned long long) to 32-bit int.
Moreover, even in 32-bit builds, when both size_t and int are 32-bit integers, you have signed/unsigned mismatch! In fact, in this case size_t is an unsigned 32-bit integer, while int is signed.
This is not a problem for strings of reasonable length. But, for example, if you happen to have a 3 GB string, in 32-bit builds a conversion from size_t to int will generate a negative number, and a negative length for a string doesn’t make sense. On the other hand, in 64-bit builds, if you a 5 GB string, converting from size_t to int will produce an int value of 1 GB, which is not the original string length.
The following table summarizes these kinds of bugs:
Build mode
size_t Type
int Type
Potential Bug when converting from size_t to int
64-bit
64-bit unsigned integer
32-bit signed integer
A “very big number” (e.g. 5GB) can be converted to an incorrect smaller number (e.g. 5GB -> 1GB)
32-bit
32-bit unsigned integer
32-bit signed integer
A “very big number” (e.g. 3GB) can be converted to a negative number (e.g. 3GB -> -1GB).
Potential bugs with size_t-to-int conversions
Note a few things:
size_t is an unsigned integer in both 32-bit and 64-bit target architectures (or build modes). However, its size does change.
int is always a 32-bit signed integer, in both 32-bit and 64-bit build modes.
This table applies to the Microsoft Visual C++ compiler (tested with VS 2019).
You can have some fun experimenting with these kinds of bugs with this simple C++ code:
// Testing "interesting" bugs with size_t-to-int conversions.
// Compiled with Microsoft Visual C++ in Visual Studio 2019
// by Giovanni Dicanio
#include <iostream> // std::cout
#include <limits> // std::numeric_limits
int main()
{
using std::cout;
#ifdef _M_AMD64
cout << " 64-bit build\n";
const size_t s = 5UI64 * 1024 * 1024 * 1024; // 5 GB
#else
cout << " 32-bit build\n";
const size_t s = 3U * 1024 * 1024 * 1024; // 3 GB
#endif
const int n = static_cast<int>(s);
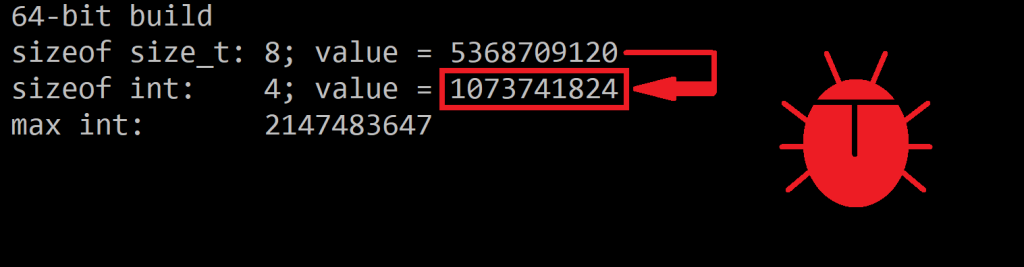
cout << " sizeof size_t: " << sizeof(s) << "; value = " << s << '\n';
cout << " sizeof int: " << sizeof(n) << "; value = " << n << '\n';
cout << " max int: " << (std::numeric_limits<int>::max)() << '\n';
}
Sample bogus conversion: a 5 giga size_t value is “silently” converted to a 1 giga int value
(Note: Bug icon designed by me 🙂 Copyright (c) All Rights Reserved)
So, these conversions from size_t to int can be dangerous and bug-prone, in both 32-bit and 64-bit builds.
Note that, if you just try to pass a size_t value to a parameter expecting an int value, without static_cast<int>, the VC++ compiler will correctly emit warning messages. And these should trigger some “red lights” in your head and suggest that your C++ code needs some attention.
Writing Safer Conversion Code
To avoid the above problems and subtle bugs with size_t-to-int conversions, you can check that the input size_t value can be properly and safely converted to int. In such positive case, you can use C++ static_cast<int> to perform the conversion, and correctly suppress C++ compiler warning messages . Else, you can throw an exception to signal the impossibility of a meaningful conversion.
For example:
// utf16.length() is the length of the input UTF-16 std::wstring,
// stored as a size_t value.
// If the size_t length exceeds the maximum value that can be
// stored into an int, throw an exception
constexpr int kIntMax = (std::numeric_limits<int>::max)();
if (utf16.length() > static_cast<size_t>(kIntMax))
{
throw std::overflow_error(
"Input string is too long: size_t-length doesn't fit into int.");
}
// The value stored in the size_t can be *safely* converted to int:
// you can use static_cast<int>(utf16.length()) for that purpose.
Note that I used std::numeric_limits from the C++ <limits> header to get the maximum (positive) value that can be stored in an int. This value is returned by std::numeric_limits<int>::max().
Fixing an Ugly Situation of Naming Conflict with max
Unfortunately, since Windows headers already define max as a preprocessor macro, this can create a parsing problem with the maxmethod name of std::numeric_limits from the C++ Standard Library. As a result of that, code invoking std::numeric_limits<int>::max() can fail to compile. To fix this problem, you can enclose the std::numeric_limits::max method call with an additional pair of parentheses, to prevent against the aforementioned macro expansion:
// This could fail to compile due to Windows headers
// already defining "max" as a preprocessor macro:
//
// std::numeric_limits<int>::max()
//
// To fix this problem, enclose the numeric_limits::max method call
// with an additional pair of parentheses:
constexpr int kIntMax = (std::numeric_limits<int>::max)();
// ^ ^
// | |
// *------- additional ( ) ------*
Note: Another option to avoid the parsing problem with “max” could be to #define NOMINMAX before including <Windows.h>, but that may cause additional problems with some Windows Platform SDK headers that do require these Windows-specific preprocessor macros (like <GdiPlus.h>). As an alternative, the INT_MAX constant from <limits.h> could be considered instead of the std::numeric_limits class template.
Widening Your Perspective of size_t-to-int Conversions and Wrapping Up
While I took the current series of blog posts on Unicode conversions as an occasion to discuss these kinds of subtle size_t-to-int bugs, it’s important to note that this topic is much more general. In fact, converting from a size_t value to an int can happen many times when writing C++ code that, for example, uses C++ Standard Library classes and functions that represent lengths or counts of something (e.g. std::[w]string::length, std::vector::size) with size_type/size_t, and interacts with Win32 APIs that use int instead (like the aforementioned WideCharToMultiByte and MultiByteToWideChar APIs). Even ATL/MFC’s CString uses int (not size_t) to represent a string length. And similar problems can happen with third party libraries as well.
A reusable convenient C++ helper function can be written to safely convert from size_t to int, throwing an exception in case of impossible meaningful conversion. For example:
// Safely convert from size_t to int.
// Throws a std::overflow_error exception if the conversion is impossible.
inline int SafeSizeToInt(size_t sizeValue)
{
constexpr int kIntMax = (std::numeric_limits<int>::max)();
if (sizeValue > static_cast<size_t>(kIntMax))
{
throw std::overflow_error("size_t value is too big to fit into an int.");
}
return static_cast<int>(sizeValue);
}
Wrapping up, it’s also worth noting and repeating that, in case of strings of reasonable length (not certainly a 3 GB or 5 GB string), converting a length value from size_t to an int with a simple static_cast<int> doesn’t cause any problems. But if you want to write more robust C++ code that is prepared to handle even gigantic strings (maybe maliciously crafted on purpose?), an additional check and potentially throwing an exception is a good safer option.
std::string storing UTF-8-encoded text is a good option for C++ cross-platform code. Let’s discuss how to convert between that and UTF-16-encoded wstrings, using direct Win32 API calls.
Using the same coding style of the previous blog post, the conversion function prototypes can look like this:
// Convert from UTF-16 to UTF-8
std::string ToUtf8(std::wstring const& utf16);
// Convert from UTF-8 to UTF-16
std::wstring ToUtf16(std::string const& utf8);
As an alternative, you may consider the C++ Standard Library snake_case style, and the various std::to_string and std::to_wstring overloaded functions, and use something like this:
// Convert from UTF-16 to UTF-8
std::string to_uf8_string(std::wstring const& utf16);
// Convert from UTF-8 to UTF-16
std::wstring to_utf16_wstring(std::string const& utf8);
Anyway, let’s keep the former coding style already used in the previous blog post.
The conversion code is very similar to what you already saw for the ATL CString case.
In particular, considering the UTF-16-to-UTF-8 conversion, you can start with the special case of an empty input string:
std::string ToUtf8(std::wstring const& utf16)
{
// Special case of empty input string
if (utf16.empty())
{
// Empty input --> return empty output string
return std::string{};
}
Then you can invoke the WideCharToMultiByte API to figure out the size of the destination UTF-8 string:
// Get the length, in chars, of the resulting UTF-8 string
const int utf8Length = ::WideCharToMultiByte(
CP_UTF8, // convert to UTF-8
kFlags, // conversion flags
utf16.data(), // source UTF-16 string
utf16Length, // length of source UTF-16 string, in wchar_ts
nullptr, // unused - no conversion required in this step
0, // request size of destination buffer, in chars
nullptr, nullptr // unused
);
if (utf8Length == 0)
{
// Conversion error: capture error code and throw
...
}
Note that, while in case of CString, you could simply pass CString instances to WideCharToMultiByte parameters expecting a const wchar_t* (thanks to the implicit conversion from CStringW to const wchar_t*), with std::wstring you have explicitly invoke a method to get that read-only wchar_t pointer. I invoked the wstring::data method; another option is to call the wstring::c_str method.
Moreover, you can define a custom C++ exception class to represent a conversion error, and throw instances of this exception on failure. For example, you could derive that exception from std::runtime_error, and add a DWORD data member to represent the error code returned by the GetLastError Win32 API.
Once you know the size for the destination UTF-8 string, you can create a std::string object capable of storing a string of proper size, using a constructor overload that takes a size parameter (utf8Length) and a fill character (‘ ‘):
// Make room in the destination string for the converted bits
std::string utf8(utf8Length, ' ');
To get write access to the std::string object’s internal buffer, you can invoke the std::string::data method:
char* utf8Buffer = utf8.data();
Now you can invoke the WideCharToMultiByte API for the second time, to perform the actual conversion, using a destination string of proper size created above:
// Do the actual conversion from UTF-16 to UTF-8
int result = ::WideCharToMultiByte(
CP_UTF8, // convert to UTF-8
kFlags, // conversion flags
utf16.data(), // source UTF-16 string
utf16Length, // length of source UTF-16 string, in wchar_ts
utf8Buffer, // pointer to destination buffer
utf8Length, // size of destination buffer, in chars
nullptr, nullptr // unused
);
if (result == 0)
{
// Conversion error: capture error code and throw
...
}
Finally, you can simply return the result UTF-8 string back to the caller:
return utf8;
} // End of function ToUtf8
Note that with C++ Standard Library strings you don’t need the GetBuffer/ReleaseBuffer “dance” required by ATL CStrings.
I developed an easy-to-use C++ header-only library containing compilable code implementing these Unicode UTF-16/UTF-8 conversions using std::wstring/std::string; you can find it in this GitHub repo of mine.
Some considerations on writing portable C++ code involving Unicode text across Windows and Linux.
Someone was developing some C++ code that was meant to be portable across Windows and Linux. They were using std::wstring to represent Unicode UTF-16-encoded strings in their Windows C++ code, and they thought that they could use the same std::wstring class to represent UTF-16-encoded text on Linux as well.
In other words, they were convinced that wchar_t and std::wstring were portable across Windows and Linux.
First, I asked them: “What do you mean by portable?”
If by “portable” you mean that the symbols are defined on both Windows and Linux platforms, then wchar_t and std::wstring (which is an instantiation of the std::basic_string class template with the wchar_t character type) are “portable”.
But, if by “portable” you mean that those symbols are defined on both platforms and they have the same meaning, then, I’m sorry, but wchar_t and std::wstring are not portable across Windows and Linux.
In fact, if you try to print out the sizeof(wchar_t), you’ll get 2 on C++ code compiled on Windows with the MSVC compiler, and 4 on GCC on Linux. In other words, wchar_t is 2-byte long on Windows, and 4-byte long on Linux!
In fact, you can use wchar_t and std::wstring to represent Unicode UTF-16-encoded text on Windows. And you can use wchar_t and std::wstring to represent Unicode UTF-32-encoded text on Linux.
If you want to write portable C++ code to represent Unicode UTF-16 text, you can use the char16_t character type for code units, and the corresponding std::u16string class for strings. Both char16_t and std::u16string have been introduced in C++11.
Or, you can switch gears and represent your Unicode text in a portable way using the UTF-8 encoding and the std::string class. If your C++ toolchain has some support for C++20 features, you can use the std::u8string class, and the corresponding char8_t character type for code units.