Someone was developing some C++ code that was meant to be portable across Windows and Linux. They were using std::wstring to represent Unicode UTF-16-encoded strings in their Windows C++ code, and they thought that they could use the same std::wstring class to represent UTF-16-encoded text on Linux as well.
In other words, they were convinced that wchar_t and std::wstring were portable across Windows and Linux.
First, I asked them: “What do you mean by portable?”
If by “portable” you mean that the symbols are defined on both Windows and Linux platforms, then wchar_t and std::wstring (which is an instantiation of the std::basic_string class template with the wchar_t character type) are “portable”.
But, if by “portable” you mean that those symbols are defined on both platforms and they have the same meaning, then, I’m sorry, but wchar_t and std::wstring are not portable across Windows and Linux.
In fact, if you try to print out the sizeof(wchar_t), you’ll get 2 on C++ code compiled on Windows with the MSVC compiler, and 4 on GCC on Linux. In other words, wchar_t is 2-byte long on Windows, and 4-byte long on Linux!
In fact, you can use wchar_t and std::wstring to represent Unicode UTF-16-encoded text on Windows. And you can use wchar_t and std::wstring to represent Unicode UTF-32-encoded text on Linux.
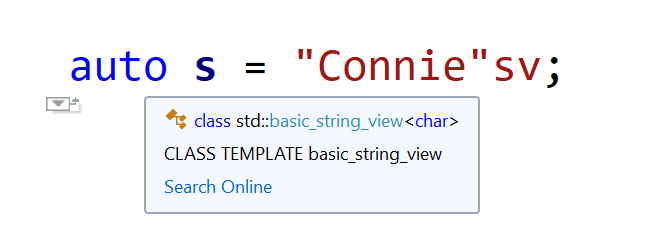
If you want to write portable C++ code to represent Unicode UTF-16 text, you can use the char16_t character type for code units, and the corresponding std::u16string class for strings. Both char16_t and std::u16string have been introduced in C++11.
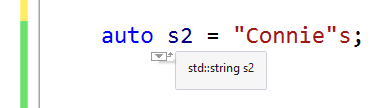
Or, you can switch gears and represent your Unicode text in a portable way using the UTF-8 encoding and the std::string class. If your C++ toolchain has some support for C++20 features, you can use the std::u8string class, and the corresponding char8_t character type for code units.