I started learning Windows Win32 API programming in C and C++ on Windows 95 (I believe it was Windows 95 OSR 2, in about late 1996 or early 1997, with Visual C++ 4). Back then, the common coding pattern was to use char for string characters (as in Amiga and MS-DOS C programming). For example, the following is a code snippet extracted from the HELLOWIN.C source code from the “Programming Windows 95” book by Charles Petzold:
static char szAppName[] = "HelloWin";
// ...
hwnd = CreateWindow(szAppName,
"The Hello Program",
...
After some time, I learned about the TCHAR model, and the wchar_t-based Unicode versions of Windows APIs, and the option to compile the same C/C++ source code in ANSI (char) or Unicode (wchar_t) mode using TCHAR instead of char.
In fact, the next edition of the aforementioned Petzold’s book (i.e. the fifth edition, in which the title went back to the original “Programming Windows”, without explicit reference to a specific Windows version) embraced the TCHAR model, and used TCHAR instead of char.
Using the TCHAR model, the above code would look like this, with char replaced by TCHAR:
static TCHAR szAppName[] = TEXT("HelloWin");
// ...
hwnd = CreateWindow(szAppName,
TEXT("The Hello Program"),
...
Note that TCHAR is used instead of char, and the string literals are enclosed or “decorated” with the TEXT(“…”) preprocessor macro. Note however that, in both cases, the same CreateWindow name is used as the API identifier.
Note that Visual C++ 4, 5, 6 and .NET 2003 all defaulted to ANSI/MBCS (i.e. 8-bit char strings, with TCHAR expanded to char).
When I moved to Windows XP, and was still using the great Visual C++ 6 (with Service Pack 6), the common “modern” pattern for international software was to just drop ANSI/MBCS 8-bit char strings, and use Unicode (UTF-16) with wchar_t at the Windows API boundary. The new Unicode-only version of the above code snippet became something like this:
static wchar_t szAppName[] = L"HelloWin";
// ...
hwnd = CreateWindow(szAppName,
L"The Hello Program",
...
Note that wchar_t is used this time instead of TCHAR, and string literals are decorated with L”…” instead of TEXT(“…”). The same CreateWindow API name is used. Note that this kind of code compiles just fine in Unicode (UTF-16) builds, but will fail to compile in ANSI/MBCS builds. That is because in ANSI/MBCS builds, CreateWindow, which is a preprocessor macro, will be expanded to CreateWindowA (the real API name), and CreateWindowA expects 8-bit char strings, not wchar_t strings.
On the other hand, in Unicode (UTF-16) builds, CreateWindow is expanded to CreateWindowW, which expects wchar_t strings, as provided in the above code snippet.
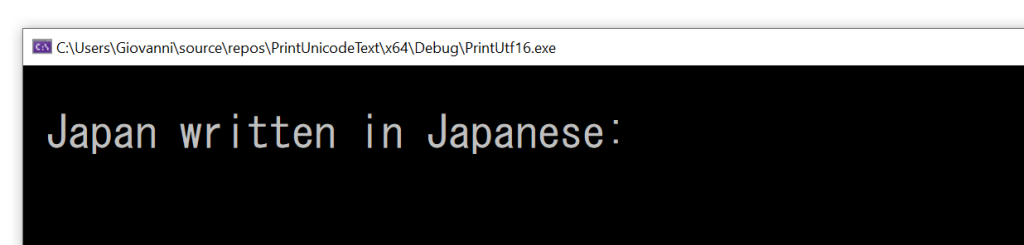
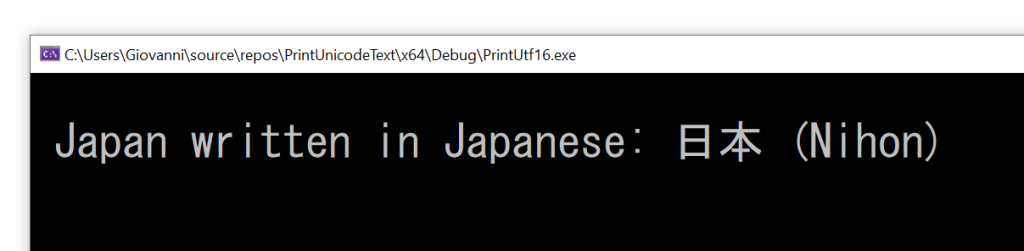
One of the problems with “ANSI/MBCS” (as they are identified in Visual Studio IDE) 8-bit char strings for international software was that “ANSI” was just insufficient for representing characters like Japanese kanjis or Chinese characters, just to name a few. While you may not care about those if you are only interested in writing programs for English-speaking customers, things become very different if you want to develop software for an international market.
I have to say that “ANSI” was a bit ambigous as a code page term. To be more precise, one of the most popular encoding for 8-bit char strings on Windows was Windows code page 1252, a.k.a. CP-1252 or Windows-1252. If you take a look at the representable characters in CP-1252, you’ll see that it is fine for English and Western Europe languages (like Italian), but it is insufficient for Japanese or Chinese, as their “characters” are not represented in there.
Note that CP-1252 is not even sufficient for some Eastern Europe languages, which are better covered by another code page: Windows-1250.
Another problem that arises with these 8-bit char encodings is ambiguity. For example, the same byte 0xC8 represents È (upper case E grave) in Windows-1252, but it maps to this completely different grapheme Č in Windows-1250.
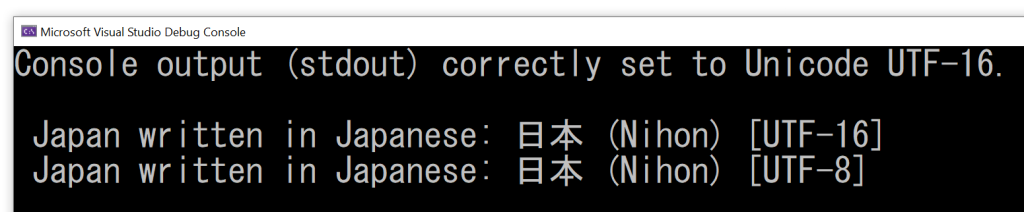
So, moving to Unicode UTF-16 and wchar_t in Windows native API programming solved these problems.
Note that, starting with Visual C++ 2005 (that came with Visual Studio 2005), the default setting for C/C++ code was using Unicode (UTF-16) and wchar_t, instead of ANSI/MBCS as in previous versions.
More recently, starting with some edition of Windows 10 (version 1903, May 2019 Update), there is an option to set the default “code page” for a process to Unicode UTF-8. In other words, the 8-bit -A versions of the Windows APIs can default to Unicode UTF-8, instead of some other code page.
So, for some Windows programmers, the pendulum is swinging back to char!