How to pass ATL/MFC CString objects to functions and methods expecting C++ string views?
Suppose that you have a C++ function or method that takes a string view as input:
void DoSomething(std::wstring_view sv)
{
// Do stuff ...
}
This function is invoked from some ATL or MFC code that uses the CString class. The code is built with Visual Studio C++ compiler in Unicode mode. So, CString is actually CStringW. And, to make things simpler, the matching std::wstring_view is used by DoSomething.
How can you pass a CString object to that function expecting a string view?
If you try directly passing a CString object like this:
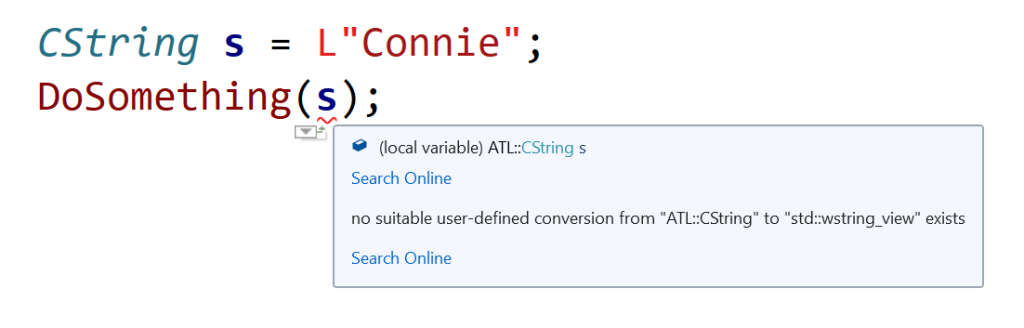
CString s = L"Connie";
DoSomething(s); // *** Doesn't compile ***
you get a compile-time error. Basically, the C++ compiler complains about no suitable user-defined conversion from ATL::CString to std::wstring_view exists.
Visual Studio 2019 IDE squiggles C++ code directly passing CString to a function expecting a wstring_view
So, how can you fix that code?
Well, since there is a wstring_view constructor overload that creates a viewfrom a null-terminated character string pointer, you can invoke the CString::GetString method, and pass the returned pointer to the DoSomething function expecting a string view parameter, like this:
// Pass the CString object 's' to DoSomething
// as a std::wstring_view
DoSomething(s.GetString());
Now the code compiles correctly!
Important Note About String Views
Note that wstring_view is just a view to a string, so you must pay attention that the pointed-to string is valid for at least all the time you are referencing it via the string view. In other words, pay attention to dangling references and string views that refer to strings that have been deallocated or moved elsewhere in memory.
How can you print Unicode text to the Windows console in your C++ programs? Let’s discuss both the UTF-16 and UTF-8 encoding cases.
Suppose that you want to print out some Unicode text to the Windows console. From a simple C++ console application created in Visual Studio, you may try this line of code inside main:
std::wcout << L"Japan written in Japanese: \x65e5\x672c (Nihon)\n";
The idea is to print the following text:
Japan written in Japanese: 日本 (Nihon)
The Unicode UTF-16 encoding of the first Japanese kanji is 0x65E5; the second kanji is encoded in UTF-16 as 0x672C. These are embedded in the C++ string literal sent to std::wcout using the escape sequences \x65e5 and \x672c respectively.
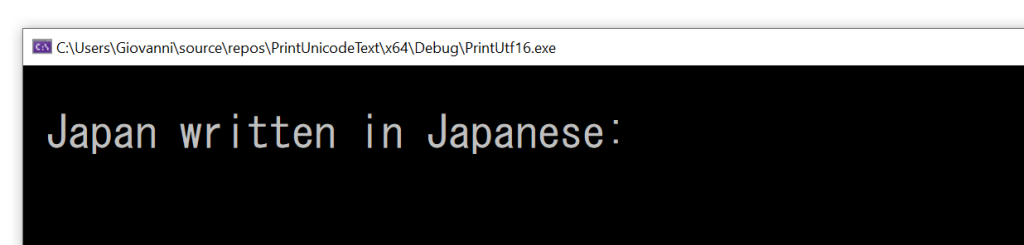
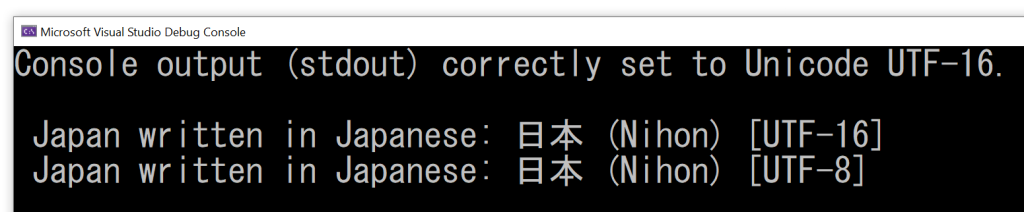
If you try to execute the above code, you get the following output:
Wrong output: the Japanese kanjis are missing!
As you can see, the Japanese kanjis are not printed. Moreover, even the “standard ASCII” characters following those (i.e.: “(Nihon)”) are missing. There’s clearly a bug in the above code.
How can you fix that?
Well, the missing piece is setting the proper translation mode for stdout to Unicode UTF-16, using _setmode and the _O_U16TEXT mode parameter.
// Change stdout to Unicode UTF-16
_setmode(_fileno(stdout), _O_U16TEXT);
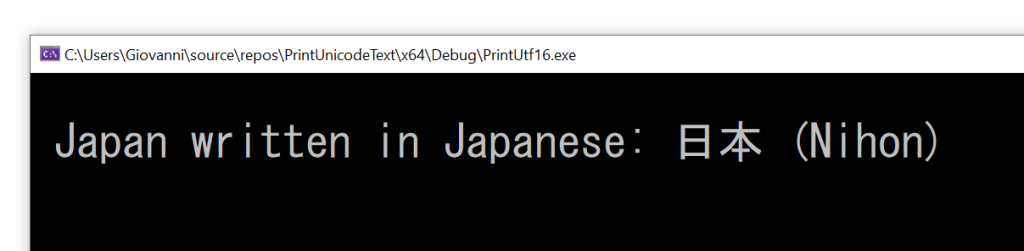
Now the output is what you expect:
The correct output of Unicode UTF-16 text.
The complete compilable C++ code follows:
// Printing Unicode UTF-16 text to the Windows console
#include <fcntl.h> // for _setmode
#include <io.h> // for _setmode
#include <stdio.h> // for _fileno
#include <iostream> // for std::wcout
int main()
{
// Change stdout to Unicode UTF-16
_setmode(_fileno(stdout), _O_U16TEXT);
// Print some Unicode text encoded in UTF-16
std::wcout << L"Japan written in Japanese: \x65e5\x672c (Nihon)\n";
}
(The above code was compiled with VS 2019 and executed in the Windows 10 command prompt.)
Note that the font you use in the Windows console must support the characters you want to print; in this example, I used the MS Gothic font to show the Japanese kanjis.
The Unicode UTF-8 Case
What about printing text using Unicode UTF-8 instead of UTF-16 (especially with all the suggestions about using “UTF-8 everywhere“)?
Well, you may try to invoke _setmode and this time pass the UTF-8 mode flag _O_U8TEXT (instead of the previous _O_U16TEXT), like this:
// Change stdout to Unicode UTF-8
_setmode(_fileno(stdout), _O_U8TEXT);
And then send the UTF-8 encoded text via std::cout:
// Print some Unicode text encoded in UTF-8
std::cout << "Japan written in Japanese: \xE6\x97\xA5\xE6\x9C\xAC (Nihon)\n";
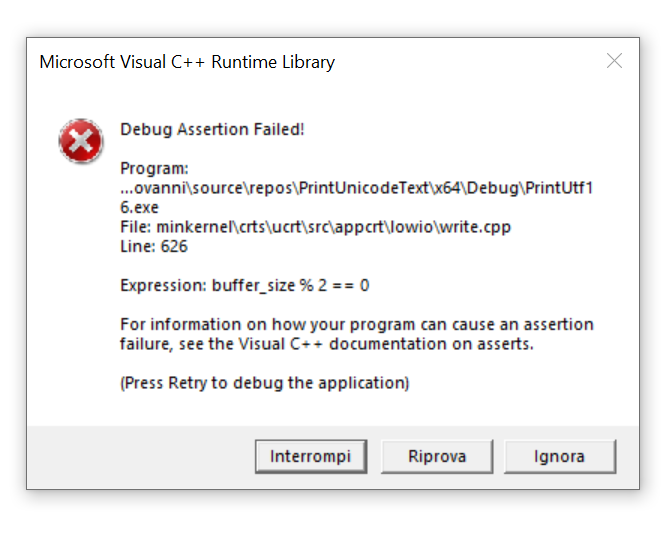
If you build and run that code, you get… an assertion failure!
Visual C++ assertion failure when trying to print Unicode UTF-8-encoded text.
So, it seems that this (logical) scenario is not supported, at least with VS2019 and Windows 10.
How can you solve this problem? Well, an option is to take the Unicode UTF-8 encoded text, convert it to UTF-16 (for example using this code), and then use the method discussed above to print out the UTF-16 encoded text.
In this course, you’ll learn how to implement some fundamental data structures and algorithms in C++from scratch, with a combination of theoretical introduction using slides, and practical C++ implementation code.
Introducing the stack data structure with an interesting metaphor
No prior data structure or algorithm theory knowledge is required. You only need a basic knowledge of C++ language features (please watch the “Prerequisites” clip in the first module for more details about that).
Explaining linear search using slides
During this course journey, you’ll also learn some practical C++ coding techniques (ranging from move semantic optimization, to proper safe array copying techniques, insertion operator overloading, etc.) that you’ll be able to use in your own C++ projects, as well.
So, this course is boththeory and practice!
Spotting a subtle bug!
Here’s just a couple of feedback notes from my reviewers:
The callouts are helpful and keep the demo engaging as you explain the code.
Peer Review
To say that this is an excellent explanation of Big-O notation would be an understatement. The way you illustrate and explain it is far better than the way it was taught to me in college!
Peer Review
Big-O doesn’t have to be boring!
Starting from this course page, you can freely play the course overview, and read a more detailed course description and table of content.
A brief introduction to the UNICODE_STRING structure used in Windows kernel mode programming.
Keeping on with the previous enumeration of string options, I’d like to mention here the UNICODE_STRING structure, used in Windows kernel mode programming.
This is a C structure, used to represent Unicode (UTF-16) strings, as its name suggests.
It’s basically a byte-length counted Unicode UTF-16 string made by a contiguous sequence of WCHARs (WCHAR is basically a typedef for wchar_t).
The UNICODE_STRING structure has three fields:
Length: This is the length, in bytes, of the contiguous sequence of WCHARs
MaximumLength: This is the length, in bytes, of the buffer that stores the contiguous sequence of WCHARs
Buffer: This is a pointer to the buffer that stores the contiguous sequence of WCHARs.
Note that the buffer can be physically larger than the string it contains. The exceeding space can be used for example when the string is concatenated with other strings during processing.
If you think of the standard std::string C++ class, or better std::wstring class, the Length field is comparable to wstring::length (except that the UNICODE_STRING’s Length is expressed in bytes, while wstring::length returns a count of wchar_ts). Similarly, UNICODE_STRING’s MaximumLength is comparable to wstring::capacity.
Note that, since UNICODE_STRINGs are byte counted, the WCHAR sequence is not required to be necessarily NUL-terminated. And, even in case of an existing NUL-terminator, the Length field does not include it in the byte count. However, since the MaximumLength field represents the length of the whole buffer, in case of a NUL-terminator, this is counted in the MaximumLength field.
There are various functions to operate on instances of UNICODE_STRING.
For example, you can use the RtlInitUnicodeString function to initialize a UNICODE_STRING. In case of a constant compile-time known Unicode string, a UNICODE_STRING instance can be initialized using the DECLARE_CONST_UNICODE_STRING macro, like this:
DECLARE_CONST_UNICODE_STRING(name, L"Connie");
The following picture shows the memory layout of a UNICODE_STRING defined as above.
Memory layout of a UNICODE_STRING
In this example, L“Connie” is made by 6 WCHARs, followed by a terminating NUL.
So, the Length field of the UNICODE_STRING structure instance, expressed as byte count, and excluding the terminating NUL, is 6 [WCHARs]*2[bytes per WCHAR] = 12 bytes.
On the other hand, the MaximumLength field represents the total length of the buffer, which, in this case, includes the terminating NUL, and it’s 14 bytes.
There are various support functions for UNICODE_STRINGs. For example, you can invoke RtlCompareUnicodeString to compare two UNICODE_STRINGs (note that this API also includes a Boolean flag for case insensitive comparisons).
Even if these are pure C APIs (and UNICODE_STRING is a pure C structure), it may be possible to wrap the UNICODE_STRING structure and its support functions in a nice C++ class, with proper operator overloading. For example, an overloaded operator== could invoke the RtlEqualUnicodeString function to determine whether two UNICODE_STRINGs strings are equal. And so on.
Just a heads up to let you know that Pluralsight has extended the 50% off sale until 11:59 p.m. MT on May 22! You get lots of high-quality courses for a very convenient price!
Well, the key is to firstcreate a BSTR from the initial std::wstring, and then pass the created BSTR to the function or class method that expects a BSTR input string.
The BSTR can be created invoking the SysAllocString API. Note that, once the BSTR is no longer needed, it must be freed calling the SysFreeString API.
The following C++ code snippet shows these concepts in action:
// The initial standard string
std::wstring ws = L"Connie is learning C++";
// Allocate a BSTR and initialize it
// with the content of the std::wstring
BSTR bstr = SysAllocString(ws.c_str());
// Invoke the function expecting the BSTR input parameter
DoSomething(bstr);
// Release the BSTR
SysFreeString(bstr);
// Avoid dangling pointers
bstr = nullptr;
The above code can be simplified, following the C++ RAII pattern and enjoying the power of C++ destructors. In fact, you can use a C++ class like ATL’s CComBSTR to wrap the raw BSTR string. In this way, the raw BSTR will be automatically deallocated when the CComBSTR object goes out of scope. That’s because the CComBSTR destructor will automatically and safely invoke SysFreeString for you.
The new simplified and safer (as incapable of leaking!) code looks like this:
// Create a BSTR safely wrapped in a CComBSTR
// from the initial std::wstring
CComBSTR myBstr(ws.c_str());
// The CComBSTR is automatically converted to a BSTR
// and passed to the function
DoSomething(myBstr);
// No need to invoke SysFreeString!
// CComBSTR destructor will *automatically* release the BSTR.
// THANK YOU C++ RAII and DESTRUCTORS!
Weird things can happen when you misinterpret a BSTR string pointer. With a sprinkle of assembly language.
Somebody has to pass a string from standard cross-platform C++ code to Windows-specific C++ code, in particular to a function that takes a BSTR string as input. For the sake of simplicity, assume that the Windows-specific function has a prototype like this:
void DoSomething(BSTR bstr)
(In real-world code, that could be a COM interface method, as well.)
The string to pass to DoSomething is stored in a std::wstring instance. The caller might have converted the original string that was encoded in Unicode UTF-8 to a Unicode UTF-16 string, and stored it in a std::wstring.
They pass the wstring to DoSomething, invoking the wstring::data method, like this:
std::wstring ws{ L"Connie is learning C++" };
DoSomething(ws.data());
The code compiles successfully. But when the DoSomething function processes the input string, a weird bug happens. To try to debug this code and figure out what’s going on, the programmer builds this code in debug mode with Visual Studio. Basically, what they observe is that the text stored in the string is output correctly, but when the string length is queried, the returned value is abnormally big.
The reported string length is 2,130,640,638. That is more than 2 billion! Of course, this string length value is completely out of scale for a string like “Connie is learning C++”.
This is a small repro code for the DoSomething function:
void DoSomething(BSTR bstr)
{
// Printing a BSTR with std::wcout?
// ...See the note at the end of the article.
std::wcout << L" String: [" << bstr << L"]\n";
// *** Get the length of the input BSTR string ***
auto len = SysStringLen(bstr);
std::wcout << L" String length: " << len << '\n';
}
And this is the output:
The input BSTR is printed out correctly, but the string length is reported as 2+ billion characters!
What is going on here? What is the origin of this bug? Why is the input string printed out correctly, but the same string is reported as being more than 2 billion characters long?
Well, the key to figure out this bug is understanding that a BSTR is not just a raw C-style wchar_t* string pointer, but it’s a pointer to a more complex and well-defined data structure.
In particular, a BSTR has a length prefix.
To get the input string length, the DoSomething function invokes the SysStringLen API. This is correct, as the input string passed to DoSomething is a BSTR. And to get the length of a BSTR string, you don’t call CRT functions like strlen or its derivatives like wcslen; instead, you call proper BSTR API functions, like SysStringLen.
The length of a BSTR is a value written as a header, before the contiguous sequence of characters pointed to by the BSTR. So, what SysStringLen likely does, is adjusting the input BSTR pointer to read the length-prefix header, and return that value back to the caller. Basically, getting the string length of a BSTR is fast O(1) constant-time operation (much faster than a O(N) operation performed by strlen/wcslen).
So, why is this 2,130,640,638 (2B+) magic number returned as length?
A Bit of Assembly Language Comes to the Rescue
I started programming at direct hardware level on the Commodore 64 and Amiga, and I love assembly!
These days I think modern C and C++ compilers do a great job in producing high-quality assembly code. However, I think that being able to read some assembly can come in handy even in these modern days!
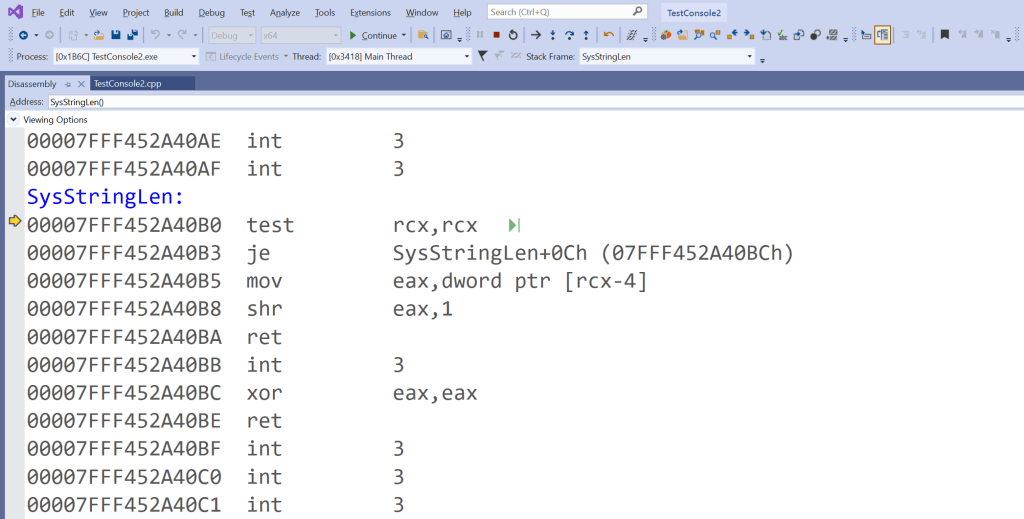
So, let’s take a look at some assembly code associated with the SysStringLen function:
SysStringLen’s assembly code shown in Visual Studio
The first assembly instruction in SysStringLen is:
test rcx, rcx
Followed by a JE conditional jump:
je SysStringLen+0Ch
This assembly code is basically checking if the RCX register is zero.
In fact, the x86/AMD64 assembly TEST instruction performs a bitwise AND on two operands. In this case, the two operands are both the value stored in the RCX register. If RCX contains the value zero (i.e. all its bits are 0), the AND operation results in zero, too. In this case, the ZF (Zero Flag) is set. As a consequence of that, the following JE instruction jumps to the instruction located at SysStringLen+0Ch, that is:
xor eax, eax
This assembly instruction performs a XOR on the content of EAX with itself. The result of that is zeroing out the EAX register.
Then, the function returns with a RET instruction.
So, what is going on here?
Well, the RCX register contains the input BSTR pointer. So, this initial assembly code is basically checking for a NULL BSTR, and, if that’s the case, it returns 0 back to the caller. This is because a NULL BSTR is considered an empty string, whose length is zero.
So, the above assembly code is basically equivalent to the following C/C++ code:
if (bstr == NULL) {
return 0;
}
But this is not the case for the input BSTR string we are considering!
So, if you execute step by step the above code, the JE jump is not taken, and the next assembly instruction that gets executed is:
mov eax, dword ptr [rcx-4]
This assembly code is basically taking the value stored in RCX, which is the input BSTR pointer. Then it adjusts the pointer to point 4 bytes backward. In this way, the pointer is pointing to the length-prefix header! So, the BSTR length value, stored in this header, is written into the EAX register.
This is basically equivalent to the following C/C++ code:
UINT len = *((UINT*)(((BYTE*)bstr) - 4));
The following instruction to be executed is:
shr eax, 1
This is a right shift of the EAX register by one bit. The result of that operation is dividing the value of EAX by two. This is basically equivalent to:
len /= 2;
Why does SysStringLen do that?
Well, the reason for that is because the string length is expressed in byte count in the header. But the returned length is expressed as count of wchar_ts. Since each wchar_t occupies two bytes in memory, you have to divide by two to convert from count in bytes to count in wchar_ts.
Finally, the RET instruction returns back to the calling code. So, when SysStringLen returns, the caller will find the BSTR string length, expressed as count of wchar_ts, in the EAX register.
Memory Analysis and the “No Man’s Land” Byte Sequence
Now you know what the assembly code of the SysStringLen does. But you may still ask: “Why that 2+ billion string length??”.
Well, the final piece of this puzzle is taking a look at the memory content when the SysStringLen function is invoked.
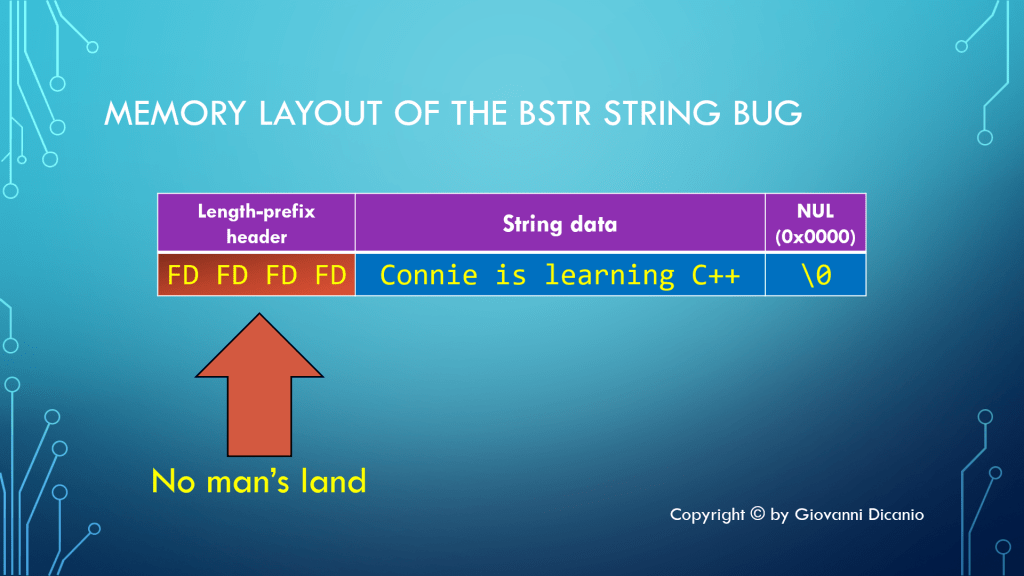
Remember that the DoSomething function expected a BSTR. The caller passed the content of a std::wstring, invoking wstring::data instead. If you take a look at the computer memory, the situation is something like what is shown below:
The memory layout of the BSTR string bug: expecting a length prefix that wasn’t there.
Before the wstring sequence of characters, there are some bytes filled with the 0xFD pattern. In particular, the 0xfdfdfdfd sequence is used to mark the area of memory before a debug heap allocated block. This is a kind of “guard” byte sequence, that delimits debug heap allocated memory blocks. This is sometimes referred to as “no man’s land”.
Of course, SysStringLen assumes that the passed string pointer represents a BSTR, and the bytes immediately before the pointed memory represent a valid length-prefix header. But in this case the pointer is a simple raw C-style string pointer (that is owned by the std::wstring object), not a full-fledged BSTR with a length prefix.
So, SysStringLen reads the 0xfdfdfdfd byte sequence, and interprets it as a BSTR length prefix.
Note that 0xfdfdfdfd expressed in base ten corresponds to the integer value 4,261,281,277. That’s something around 4 billion, not the circa-2 billion value we get here. So, why we do get 2 billion and not 4 billion?
Well, don’t forget the SHR (shift to the right) instruction towards the end of the SysStringLen assembly code! In fact, as already discussed, SysStringLen uses SHR to divide the initial length value by two, as the length is stored in the BSTR header as a count of bytes, but the value returned by SysStringLen is expressed as a count of wchar_ts.
So, start from the “no man’s land” byte sequence 0xfdfdfdfd. Right-shift it by one bit, making it 0x7efefefe. Convert that value back to decimal, and you get 2,130,640,638, which is the initial “magic value” returned as the string length! So: Mystery Solved! 😊
Side Note: Why Was the BSTR Printed Out Correctly with wcout?
That is a very good question! Well, when you pass the BSTR pointer to wcout, it is interpreted as a raw C-style string pointer to a NUL-terminated string (wchar_t*). Since the BSTR contains a NUL terminator at its end, things work correctly: wcout prints the various string characters, and stops at the terminating NUL.
However, note that we were kind of lucky. In fact, if the BSTR contained embedded NULs (which is possible, as a BSTR is length-prefixed), wcout would have stopped at the first NUL in the sequence; so, in that case, only the first part of the BSTR string would have been printed out.
Let’s continue the discussion on string types available for C++ programmers, this time introducing a Windows-specific string type: the BSTR.
Continuing the previous enumeration of some available C++ string options, let’s focus this time on a Windows platform-specific type of string: BSTR. BSTR is a string type that is used in Windows programming by COM, OLE Automation, and even interop functions to pass strings between C++ native code and .NET managed code.
The acronym stands for Basic String, which is tied to its historical origins related to Visual Basic and OLE Automation.
So, what does this BSTR string type look like?
Well, it’s defined in the Windows SDK <wtypes.h> header like this (comments and annotations stripped out):
typedef OLECHAR *BSTR;
So, it’s a raw pointer to an OLECHAR. And, what is an OLECHAR? If you use Visual Studio, you can right click on the unknown OLECHAR symbol, and select “Go To Definition” in the context menu, or just press F12. This leads to:
typedef WCHAR OLECHAR;
So, OLECHAR is basically a typedef for a WCHAR. And, recursively, what is a WCHAR?
Well, same F12 trick, and you land on the following line in <winnt.h>:
typedef wchar_t WCHAR; // wc, 16-bit UNICODE character
So, “unwinding” the above search stack, BSTR is basically a typedef to a wchar_t* raw pointer.
So, does it mean that you can happily use both BSTR and wchar_t* C-style strings interchangeably in your C++ code?
No way! Unless you want to introduce nasty bugs in your code.
In fact, in addition to its raw typedef definition, a BSTR has a well-defined memory layout, and allocation and deallocation requirements.
Allocating and Freeing Memory for BSTRs
In particular, a BSTR must be allocated using COM specific memory allocation functions, like SysAllocString (and similar functions like SysAllocStringLen, etc.).
BSTR myBstr = SysAllocString(L"Connie");
And, symmetrically, it must be freed using SysFreeString:
In other words, you can’t just invoke new[] and delete[] or malloc and free to allocate and release memory for your BSTR strings. Again, that would cause nasty bugs in your code!
As a side note: These BSTR functions (SysAllocString, SysFreeString, etc.) are declared in the <OleAuto.h> header, which reminds us of the historical connection between BSTR and OLE Automation.
The BSTR Memory Layout
Note also that, despite its simple type-system definition of wchar_t*, a BSTR has a well specified structure in computer memory.
In particular, considering the above “Connie” example, such a BSTR looks like this in memory:
Memory layout of a BSTR string
There is a 4-byte (32-bit) header, before the wchar_t pointed by the BSTR pointer, that is a 32-bit integer that stores the number of bytes in the following string data.
There is a contiguous sequence of wchar_t’s, that represents the string encoded in Unicode UTF-16.
There is a wchar_t NUL-terminator, i.e., a sequence of two bytes (16 bits) cleared to zero: 0x0000.
As you can see, this is a concrete well-defined data structure associated to the BSTR pointer, with a length-prefix header, followed by the sequence of wchar_t’s, and a 2-byte NUL terminator. This is very different from a simple C-style string, like:
const wchar_t* str = L"Connie";
Note that the string length in the BSTR header is expressed in bytes. Let’s do some simple math: “Connie” has six characters; each character is a wchar_t, which occupies two bytes; so, 6 [wchar_t] * 2 [byte/wchar_t] = 12 bytes. So, 12 is the number of bytes occupied by the string data; this length value is stored in the BSTR header.
Note also that the terminating NUL is not counted in the length prefix.
Another important feature of BSTR is that a NULL (or nullptr) BSTR is equivalent to an empty string. In other words, an empty string ”” and a NULL BSTR must have the same semantics.
Note also that the sequence of contiguous wchar_ts following the BSTR header can contain embedded NULs, as the BSTR is length-prefixed.
In addition, getting the length (expressed as count of wchar_ts) for a BSTR is a fast O(1) operation, as the string stores its length in the header. You can get the length of a BSTR invoking the SysStringLen API.
Side Note: Using a BSTR as a Binary Array
As an interesting side note, sometimes the BSTR structure is used as a generic byte-array data structure instead of a proper string. In other words, since it’s length-prefixed and can potentially contain embedded zeros, a generic sequence of bytes can be stuffed in the string data part of the BSTR structure. However, I have to say that I’d prefer using a proper data structure to store a binary byte sequence, for example, in the realm of OLE Automation: a SAFEARRAY storing 8-bit unsigned integers, instead of kind of “semantically stretching” a BSTR.
An interesting bug involving the use of string_view instead of std::string const&.
Suppose that in your C++ code base you have a legacy C-interface function:
// Takes a C-style NUL-terminated string pointer as input
void DoSomethingLegacy(const char* s)
{
// Do something ...
printf("DoSomethingLegacy: %s\n", s);
}
The above function is called from a C++ function/method, for example:
void DoSomethingCpp(std::string const& s)
{
// Invoke the legacy C function
DoSomethingLegacy(s.data());
}
The calling code looks like this:
std::string s = "Connie is learning C++";
// Extract the "Connie" substring
std::string s1{ s.c_str(), 6 };
DoSomethingCpp(s1);
The string that is printed out is “Connie”, as expected.
Then, someone who knew about the new std::string_view feature introduced in C++17, modifies the above code to “modernize” it, replacing the use of std::string with std::string_view:
std::string s = "Connie is learning C++";
// Use string_view instead of string:
//
// std::string s1{ s.c_str(), 6 };
//
std::string_view sv{ s.c_str(), 6 };
DoSomethingCpp(sv);
The code is recompiled and executed. But, unfortunately, now the output has changed! Instead of the expected “Connie” substring, now the entire string is printed out:
Connie is learning C++
What’s going on here? Where does that “magic string” come from?
Analysis of the Bug
Well, the key to figure out this bug is understanding that std::string_view’s are not necessarily NUL-terminated. On the other hand, the legacy C-interface function does expect as input a C-style NUL-terminated string (passed via const char*).
In the initial code, a std::string object was created to store the “Connie” substring:
// Extract the "Connie" substring
std::string s1{ s.c_str(), 6 };
This string object was then passed via const& to the DoSomethingCpp function, which in turn invoked the string::data method, and passed the returned C-style string pointer to the DoSomethingLegacy C-interface function.
Since strings managed via std::string objects are guaranteed to be NUL-terminated, the string::data method pointed to a NUL-terminated contiguous sequence of characters, which was what the DoSomethingLegacy function expected. Everyone’s happy.
On the other hand, when std::string is replaced with std::string_view in the calling code:
// Use string_view instead of string:
//
// std::string s1{ s.c_str(), 6 };
//
std::string_view sv{ s.c_str(), 6 };
DoSomethingCpp(sv);
you lose the guarantee that the sub-string is NUL-terminated!
In fact, this time when sv.data is invoked inside DoSomethingCpp, the returned pointer points to a sequence of contiguous characters that is the original string s, which is the whole string “Connie is learning C++”. There is no NUL-terminator after “Connie” in that string, so the legacy C function that takes the string pointer just goes on and prints the whole string, not just the “Connie” substring, until it finds a NUL-terminator, which follows the last character of “Connie is learning C++”.
Figuring out the bug involving the (mis)use of string_view
So, be careful when replacing std::string const& parameters with string_views! Don’t forget that string_views are not guaranteed to be NUL-terminated! That is very important when writing or maintaining C++ code that interoperates with legacy C or C-style code.